# 函数
# 定义|调用
# 定义函数
def 函数名(参数):
代码1
代码2
......
# 调用函数
函数名(参数)
# 例子
需求:制作一个计算器,计算任意两数字之和,并保存结果。
def sum_num(a, b):
return a + b
# 用result变量保存函数返回值
result = sum_num(1, 2)
print(result)
# 函数嵌套
def testB():
print('---- testB start----')
print('这里是testB函数执行的代码...(省略)...')
print('---- testB end----')
def testA():
print('---- testA start----')
testB()
print('---- testA end----')
testA()
# 变量作用域
局部变量 局部变量是定义在函数体内部的变量,即只在函数体内部生效。
def testA(): a = 100 print(a) testA() # 100 print(a) # 报错:name 'a' is not defined全局变量 全局变量,指的是在函数体内、外都能生效的变量。
# 定义全局变量a a = 100 def testA(): print(a) # 访问全局变量a,并打印变量a存储的数据 def testB(): print(a) # 访问全局变量a,并打印变量a存储的数据 testA() # 100 testB() # 100函数内修改全局变量
a = 100 def testA(): print(a) def testB(): # global 关键字声明a是全局变量 global a a = 200 print(a) testA() # 100 testB() # 200 print(f'全局变量a = {a}') # 全局变量a = 200
# 返回值
允许多个返回值,返回多个数据的时候,默认是元组类型
def return_num():
return 1, 2
result = return_num()
print(result) # (1, 2)
# 参数
# 位置参数
位置参数:调用函数时根据函数定义的参数位置来传递参数。
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('TOM', 20, '男')
注意:传递和定义参数的顺序及个数必须一致。
# 关键字参数
通过“键=值”形式加以指定。可以让函数更加清晰、容易使用,同时也清除了参数的顺序需求。
def user_info(name, age, gender):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('Rose', age=20, gender='女')
user_info('小明', gender='男', age=16)
TIP
注意:函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序。
# 默认参数
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值
def user_info(name, age, gender='男'):
print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
user_info('TOM', 20)
user_info('Rose', 18, '女')
注意:函数调用时,如果为缺省参数传值则修改默认参数值;否则使用这个默认值。
TIP
所有位置参数必须出现在默认参数前,包括函数定义和调用
# 不定长参数
不定长参数也叫可变参数。
包裹位置传递
def user_info(*args): print(args) # ('TOM',) user_info('TOM') # ('TOM', 18) user_info('TOM', 18)TIP
注意:传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是包裹位置传递。
包裹关键字传递
def user_info(**kwargs): print(kwargs) # {'name': 'TOM', 'age': 18, 'id': 110} user_info(name='TOM', age=18, id=110)TIP
无论是包裹位置传递还是包裹关键字传递,都是一个组包的过程。
# 拆包
- 拆包:元组
def return_num(): return 100, 200 num1, num2 = return_num() print(num1) # 100 print(num2) # 200 - 拆包:字典
dict1 = {'name': 'TOM', 'age': 18} a, b = dict1 # 对字典进行拆包,取出来的是字典的key print(a) # name print(b) # age print(dict1[a]) # TOM print(dict1[b]) # 18
# 引用
# 什么是引用
在python中,值是靠引用来传递来的。
我们可以用id()来判断两个变量是否为同一个值的引用。 我们可以将id值理解为那块内存的地址标识
# 1. int类型
a = 1
b = a
print(b) # 1
print(id(a)) # 140708464157520
print(id(b)) # 140708464157520
a = 2
print(b) # 1,说明int类型为不可变类型
print(id(a)) # 140708464157552,此时得到是的数据2的内存地址
print(id(b)) # 140708464157520
# 2. 列表
aa = [10, 20]
bb = aa
print(id(aa)) # 2325297783432
print(id(bb)) # 2325297783432
aa.append(30)
print(bb) # [10, 20, 30], 列表为可变类型
print(id(aa)) # 2325297783432
print(id(bb)) # 2325297783432
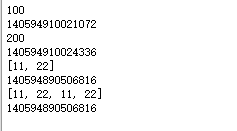
# 引用当做实参
def test1(a):
print(a)
print(id(a))
a += a
print(a)
print(id(a))
# int:计算前后id值不同
b = 100
test1(b)
# 列表:计算前后id值相同
c = [11, 22]
test1(c)
# 可变类型和不可变类型
所谓可变类型与不可变类型是指:数据能够直接进行修改,如果能直接修改那么就是可变,否则是不可变.
- 可变类型
- 列表
- 字典
- 集合
- 不可变类型
- 整型
- 浮点型
- 字符串
- 元组
# 递归
# 特点
- 函数内部自己调用自己
- 必须有出口
# 例子
3以内累加
# 3 + 2 + 1
def sum_numbers(num):
# 1.如果是1,直接返回1 -- 出口
if num == 1:
return 1
# 2.如果不是1,重复执行累加并返回结果
return num + sum_numbers(num-1)
sum_result = sum_numbers(3)
# 输出结果为6
print(sum_result)
# lambda表达式
# 语法
lambda 参数列表 : 表达式
TIP
- lambda表达式的参数可有可无,函数的参数在lambda表达式中完全适用。
- lambda表达式能接收任何数量的参数但只能返回一个表达式的值。
# 例子
普通使用
# 函数 def fn1(): return 200 print(fn1) print(fn1()) # lambda表达式 fn2 = lambda: 100 print(fn2) #输出内存地址 print(fn2()) #输出值参数
def add(a, b): return a + b result = add(1, 2) print(result) fn1 = lambda a, b: a + b print(fn1(1, 2))带判断
fn1 = lambda a, b: a if a > b else b print(fn1(1000, 500))
# 高阶函数
把函数作为参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现
# 例子
def sum_num(a, b, f):
return f(a) + f(b)
result = sum_num(-1, 2, abs)
print(result) # 3
# map()
map(func, lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表(Python2)/迭代器(Python3)返回。
需求:计算list1序列中各个数字的2次方。
list1 = [1, 2, 3, 4, 5]
def func(x):
return x ** 2
result = map(func, list1)
print(result) # <map object at 0x0000013769653198>
print(list(result)) # [1, 4, 9, 16, 25]
# reduce()
reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累积计算。
注意:reduce()传入的参数func必须接收2个参数。 需求:计算
list1序列中各个数字的累加和。
import functools
list1 = [1, 2, 3, 4, 5]
def func(a, b):
return a + b
result = functools.reduce(func, list1)
print(result) # 15
# filter()
filter(func, lst)函数用于过滤序列, 过滤掉不符合条件的元素, 返回一个 filter 对象。如果要转换为列表, 可以使用 list() 来转换。
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
def func(x):
return x % 2 == 0
result = filter(func, list1)
print(result) # <filter object at 0x0000017AF9DC3198>
print(list(result)) # [2, 4, 6, 8, 10]