# 大模型微调
# 前置知识
对于大语言模型来说, Chat 类模型通常是在 Base 类模型的基础上,通过对话格式的微调或特殊训练得到的。基础模型(Base models)首先在大规模的文本数据上进行预训练,学习语言的基本规律、知识和语境理解能力。在这一阶段,大模型通常不会特别针对对话任务进行优化,其根本的目的还是要去学习广泛的语言表达和理解能力。然后,为了使模型更适合特定的任务,如聊天对话,这些基础模型会经过进一步的微调(fine-tuning),这往往采用的是全量微调的方法而不是所谓的高效微调。在全量微调阶段,大模型在对话数据集上进行训练,学习如何在对话上下文中生成连贯、相关且自然的回答。这一过程可能包括对特定的对话结构、回答风格或特定领域知识的优化。这种基于基础模型的微调方法使得 Chat 类模型能够在保持底层语言理解和生成能力的同时,更好地适应对话式的交互需求。
# LLama factory
LLaMA Factory是一个在GitHub上开源的项目,该项目给自身的定位是:提供一个易于使用的大语言模型(LLM)微调框架,支持LLaMA、Baichuan、Qwen、ChatGLM等架构的大模型。更细致的看,该项目提供了从预训练、指令微调到RLHF阶段的开源微调解决方案。截止目前支持约120+种不同的模型和内置了60+的数据集,同时封装出了非常高效和易用的开发者使用方法。而其中最让人喜欢的是其开发的LLaMA Board,这是一个零代码、可视化的一站式网页微调界面,它允许我们通过Web UI轻松设置各种微调过程中的超参数,且整个训练过程的实时进度都会在Web UI中进行同步更新。
LLama factory支持的模型和微调方式请查看官网
LLaMA Factory的GitHub地址如下:https://github.com/hiyouga/LLaMA-Factory/tree/main
# 前置条件
- Python >= 3.8版本,建议Python3.10版本以上
- PyTorch >= 1.13.1版本,建议 Pytorch 版本为 2.2.1
- transformers >= 4.37.2,建议 transformers 版本为 4.38.1
- CUDA >= 11.6,建议CUDA版本为12.2
# 训练
这里使用指令数据集,采用lora全参数微调qwen2-7b,
# 模型和数据集
在 Linux 命令行中输入以下命令,使用 huggingface-cli 工具将模型下载到 ~/model/qwen2,将数据集下载到 ~/data/align-anything
export HF_ENDPOINT=https://hf-mirror.com
# 下载数据集
huggingface-cli download --repo-type dataset --resume-download PKU-Alignment/Align-Anything-Instruction-100K-zh --local-dir ~/data/align-anything
# 下载模型
huggingface-cli download --resume-download Qwen/Qwen2-7B --local-dir ~/model/qwen2
https://hf-mirror.com 是huggingface代理
WARNING
由于下载的数据集有10000条数据,训练预估需要24小时,我最终使用llama factory自带的identity.json数据集进行训练
# 安装LLaMA-Factory
依次在 Linux 命令行输入以下命令:
# 从 GitHub 上下载 LLaMA-Factory 源码
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 进入 LLaMA-Factory 文件夹
cd LLaMA-Factory
# 安装相关依赖
pip install -e ".[torch,metrics]"
官方默认使用pip进行环境安装,也提供uv命令,但实际使用uv会报错,最终使用
uv pip install -e ".[torch,metrics]" --default-index https://mirrors.aliyun.com/pypi/simple/安装。
安装完成后使用 llamafactory-cli version 命令来验证是否安装成功。若命令行显示 LLaMA-Factory 的版本号,则说明安装成功
# 数据集处理
我们选择官方自带的identity.json数据集进行训练。需要替换该数据集中和标识符,自行替换即可。数据集需放置在LLaMA-Factory/data目录下
如何是使用自定义数据集或前面下载的Align-Anything.json数据集,需要修改为一下格式:
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
而我们观察 Align-Anything 数据集,不难发现它是 jsonl 的格式,并且每一条记录只包含 prompt 和 response 两个键,示例如下:
{"prompt": "主题:猫三联和狂犬疫苗能同一针注射吗?\n 描述:猫三联和狂犬疫苗能同一针注射吗?\n这个问题的答案是:", "response": "一般狂犬疫苗作为整个疫苗程序最后一针,动物大于16周,可以和最后一针三联一起接种,但是不能用一支针管,不能注射同一个部位。目前你可以去医院先他们,要求4周以后重新注射。"}
{"prompt": "你做过最大的努力是什么?\n回答答案:", "response": "两个月,从108斤瘦到80斤,160cm,80斤。然后华丽丽晕倒在学校澡堂,咱们学校第一人 我知道在将来,我不会再这么疯狂了。"}
# 数据集注册
由于 Align-Anything 并不是 LLaMA-Factory 出厂预置的数据集,因此预处理完成后,我们还需要对数据集进行注册,也就是编辑 /data/dataset_info.json 文件
# 编辑文件
vim /data/dataset_info.json
并在该 json 文件中添加一个新的键值对,格式如下:
"数据集名称": {
"file_name": "your_data_name.json",
"columns": {
"prompt": "prompt_key_in_your_data",
"query": "input_key_in_your_data",
"response": "output_key_in_your_data",
"system": "system_key_in_your_data",
"history": "history_key_in_your_data"
}
}
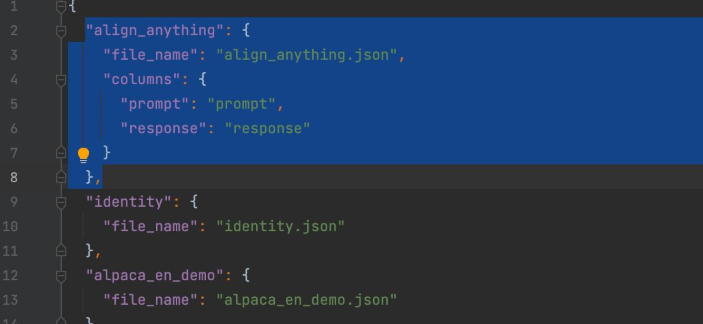
完成编辑后的效果如下,其中蓝色选中部分就是我们新添加的内容(注意在我们预处理后的 Align-Anything 数据集中,prompt 所对应的键就是 prompt,response 所对应的键就是 response,并且数据集中不包含其他键):
# 模型训练
在这一步中,由于本文采用的是 LoRA 微调方式,因此我们编辑 examples/train_lora/qwen2_lora_sft.yaml 文件
vim examples/train_lora/qwen2_lora_sft.yaml
编辑文件内容如下:
model_name_or_path: /username/model/Qwen2-7B # 声明模型地址
stage: sft # 声明训练阶段是有监督微调
do_train: true
finetuning_type: lora # 声明微调方式为 LoRA
lora_target: all # 对模型中的所有参数做微调
dataset: align_anything # 声明训练数据集
template: qwen # 声明模型模板
cutoff_len: 1024
max_samples: 103505 # 声明训练样本数量
overwrite_cache: true
preprocessing_num_workers: 16
output_dir: saves/qwen2-7b/lora/sft # 声明输出目录
logging_steps: 10
save_steps: 500
plot_loss: true
overwrite_output_dir: true
per_device_train_batch_size: 1
gradient_accumulation_steps: 8
learning_rate: 1.0e-4
num_train_epochs: 3.0
lr_scheduler_type: cosine
warmup_ratio: 0.1
bf16: true
ddp_timeout: 180000000
val_size: 0.1
per_device_eval_batch_size: 1
eval_strategy: steps
eval_steps: 500
# 执行训练命令
llamafactory-cli train examples/train_lora/qwen2_lora_sft.yaml
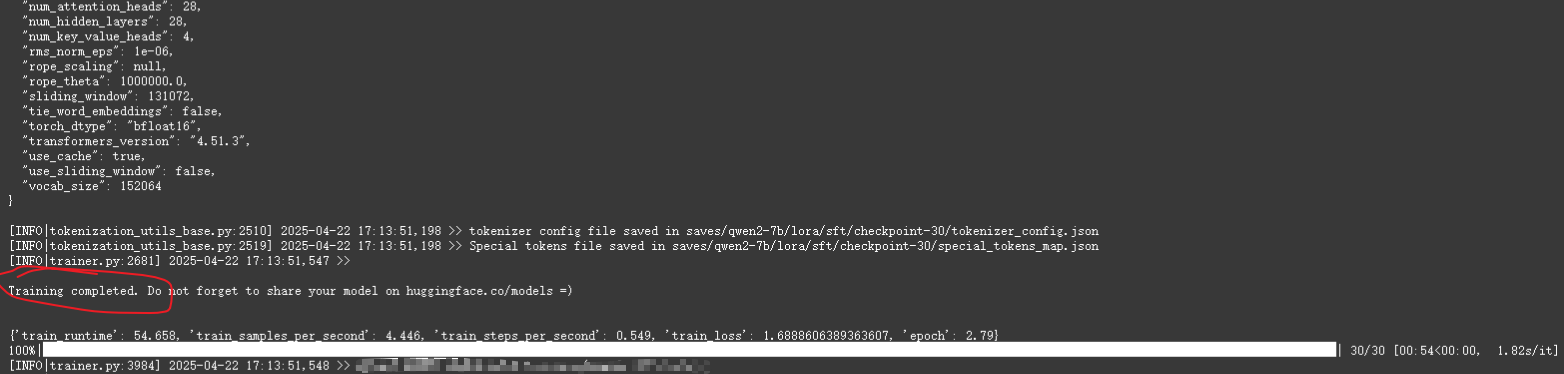
如果训练程序正常启动,命令行显示信息应如下图所示:
 训练完成
训练完成
# 参数合并
根据 LoRA 微调的原理,新学习到的参数需要与原参数相加以得到更新的参数,这个过程同样需要两步来实现。首先是编写配置文件 examples/merge_lora/qwen2_lora_sft.yaml
vim examples/merge_lora/qwen2_lora_sft.yaml
编辑文件的内容如下:
model_name_or_path: /username/model/Qwen2-7B # 原模型保存路径
adapter_name_or_path: saves/qwen2-7b/lora/sft # LoRA 参数保存路径
template: qwen
finetuning_type: lora
export_dir: models/qwen2_lora_sft # 合并后的模型存放路径
export_size: 2
export_device: cpu
export_legacy_format: false
然后执行参数融合命令:
llamafactory-cli export examples/merge_lora/qwen2_lora_sft.yaml
# 推理
推理还是分为两步实现,首先编写配置文件 examples/inference/qwen2_lora_sft.yaml
vim examples/inference/qwen2_lora_sft.yaml
编辑文件内容:
model_name_or_path: models/qwen2_lora_sft
template: qwen
然后在命令行输入如下命令
llamafactory-cli chat examples/inference/qwen2_lora_sft.yaml
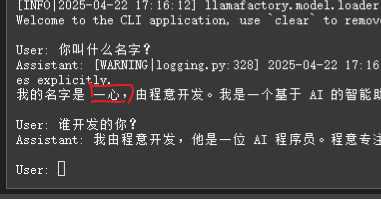
推理测试结果如下
# 参考
LLaMA-Factory 实战(一):采用 LoRA 方式对QWen2 做指令微调 (opens new window)
手把手带你微调阿里qwen2.5大模型 (opens new window)
LLaMA-Factory项目介绍及Baichuan2、Qwen和ChatGLM3的微调实践 (opens new window)