# modelscope
# 简介
ModelScope 是一个面向模型开发的开源平台,旨在促进模型开发、分享和应用。
ModelScope 提供了丰富的模型库,涵盖了各种领域的模型,包括文本生成、图像识别、语音识别等。
ModelScope 还提供了一系列工具和库,用于模型开发、训练和推理。
# 安装
ModelScope Library目前支持模型和数据集的获取和管理,以及基于PyTorch、Tensorflow等学习框架基础上进行模型训练、推理, 在Python 3.8+, Pytorch 1.11+, Tensorflow上测试可运行。
WARNING
大部分语音模型当前需要在Linux环境上使用,并且推荐使用python3.8 + tensorflow 2.13.0 + torch 2.0.1 的组合。部分模态模型可以在mac,windows等环境上安装使用,少部分模型需要tensorflow1.15.0。
# conda环境
conda create -n modelscope python=3.11
conda activate modelscope
# ModelScope Library安装
# pip包安装
ModelScope Library由 核心hub 支持,框架,以及不同领域模型的 对接组件 组成。根据您实际使用的场景,可以选择不同的安装选项。
如果只通过ModelScope SDK,或者ModelScope命令行工具下载模型,只安装ModelScope的核心hub支持:
pip install modelscope
如果需要更完整的使用ModelScope平台上的一系列框架能力,包括数据集的加载,外部模型的使用等,则推荐使用"framework"的安装选项,也就是:
pip install modelscope[framework]
要使用ModelScope来实现各种领域模型的使用,包括基于NLP、CV、语音、多模态,等不同领域的模型,来进行模型推理以及模型训练、微调等能力,则需要根据具体领域,通过安装选项,来安装额外的依赖。 同时也涉及对应的PyTorch,Tensorflow等机器学习框架的安装。
# 深度学习框架依赖的安装
注: 机器学习框架本身包通常较大,客观上在国内使用pip安装的时候,如果默认是用海外的pypi源的话,下载速度较慢。这种情况下,可以考虑通过pip的"-i"命令行选项,来手工配置仓库来源,例如"-i https://pypi.tuna.tsinghua.edu.cn/simple " 可以将配置仓库来源使用"清华源"。例如
pip3 install torch -i https://pypi.tuna.tsinghua.edu.cn/simple
这里我windows系统直接使用上述命令安装的是cpu版本的torch,没有使用cuda版本。
最终使用的官方命令安装,(未翻墙但也没限速,原因未知):pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
# 分领域ModelScope模型依赖安装
NLP模型
pip install "modelscope[nlp]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html-f 指定一个或多个 URL 或本地目录路径,pip 会在这些指定的来源中查找需要安装的包。
CV模型
pip install "modelscope[cv]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html语音模型
pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html多模态模型
pip install "modelscope[multi-modal]"科学计算
pip install "modelscope[science]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
# 注:
- 如果您已经安装过ModelScope,但是需要升级使用新版发布的Library,可以使用
pip install modelscope --upgrade - 目前极少部分部分模型仅支持tensorflow1.15.5的Linux环境使用。 其他大部分模型可以在windows、mac(x86)上安装使用。
pip install modelscope --upgrade - 语音领域中一部分模型使用了三方库SoundFile进行wav文件处理,在Linux系统上用户需要手动安装SoundFile的底层依赖库libsndfile,在Windows和MacOS上会自动安装不需要用户操作。详细信息可参考SoundFile官网。以Ubuntu系统为例,用户需要执行如下命令:
sudo apt-get update sudo apt-get install libsndfile1 - CV领域的少数模型,需要安装mmcv-full, 如果运行过程中提示缺少mmcv,请参考mmcv安装手册进行安装。 注意这里需要安装的是mmcv 1.x版本(mmcv-full),请不要安装mmcv 2.0及以上版本。 这里提供一个最简版的mmcv-full安装步骤,但是要达到最优的mmcv-full的安装效果(包括对于cuda版本的兼容),请根据自己的实际机器环境,以mmcv官方安装手册为准。
pip uninstall mmcv && pip uninstall mmcv-full # 如果已经安装过简装版本的mmcv,请先卸载 pip install -U openmim mim install mmcv-full # 如果您使用python3.10,torch 2.1.0和2.1.1,cuda 11.8.0,12.1.0,可以按照如下方式安装 # 版本1.7.0+torch2.1.1cu121 1.7.0+torch2.1.0cu121 1.7.0+torch2.1.1cu118 1.7.0+torch2.1.0cu118 pip install mmcv_full=='1.7.0+torch2.1.1cu121' -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html这里我直接执行pip install -U openmim & mim install mmcv-full这两个命令安装的。看了mmcv官方安装手册,里面也没有描述怎么根据实际环境安装。
# 模型下载
命令行下载
modelscope download --model="Qwen/Qwen2.5-0.5B-Instruct" --local_dir ./model-dirModelScope Python SDK下载模型
from modelscope import snapshot_download model_dir = snapshot_download("Qwen/Qwen2.5-0.5B-Instruct")由于模型都是通过Git存储,所以也可以在安装Git LFS后,通过git clone的方式在本地下载模型:
git lfs install git clone https://www.modelscope.cn/Qwen/Qwen2.5-0.5B-Instruct.git
# 模型加载
AutoModel 和 pipeline 是 Hugging Face Transformers 库中两种不同的加载和使用模型的方式。
# 使用AutoModel加载模型
ModelScope支持原生的pipeline推理,同时也兼容了由Transformers,Diffusers等提供的AutoModel和Pipeline的加载。
例如在安装 modelscope 和 transformers 之后,就可以通过如下代码进行LLM的推理。
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 使用ModelScope的pipeline加载模型
from modelscope.pipelines import pipeline
word_segmentation = pipeline('word-segmentation',model='damo/nlp_structbert_word-segmentation_chinese-base')
# 模型推理
不同模态多种任务,pipeline是最简单、最快捷的方法。您可以使用开箱即用的pipeline执行跨不同模式的多种任务,下面是一个pipeline完整的运行示例:
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
inference_pipeline = pipeline(
task=Tasks.auto_speech_recognition,
model='iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch',
model_revision="v2.0.4")
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_vad_punc_example.wav')
print(rec_result)
ModelScope兼容了Transformers提供的简单而统一的方法来加载预训练实例和tokenizer。这意味着您可以使用ModelScope加载AutoModel和AutoTokenizer等类。下面是一个大语言模型的完整的运行示例:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-0.5B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
对于暂时未与ModelScope SDK做原生集成的模型,可以先从ModelScope上下载模型,然后通过其他的主流库实现模型推理,以SDXL-Turbo模型为例,完整的模型推理运行示例如下:
from diffusers import AutoPipelineForText2Image
import torch
from modelscope import snapshot_download
model_dir = snapshot_download("AI-ModelScope/sdxl-turbo")
pipe = AutoPipelineForText2Image.from_pretrained(model_dir, torch_dtype=torch.float16, variant="fp16")
pipe.to("cuda")
prompt = "A cinematic shot of a baby racoon wearing an intricate italian priest robe."
image = pipe(prompt=prompt, num_inference_steps=1, guidance_scale=0.0).images[0]
image.save("image.png")
# 模型部署
分三种部署方式
- 部署开源模型为OpenAI API兼容服务
- 基于魔搭原生Pipeline进行云上部署
- 本地部署
前两种都是魔搭提供的云服务,第三种是用户自行部署。
# 使用modelscope的server服务部署
ModelScope库基于fastapi开发一个简单模型服务,可以通过一条命令拉起绝大多数模型 使用方法:
modelscope server --model_id=Qwen/Qwen-7B-Chat --revision=v1.0.5
这里的--revision参数必填,是模型git上传的版本号。
TIP
这里除了需要安装modelscope,还需要安装modelscope[server],此外还需要安装modelscope[cv|nlp|audio|multi-modal|science]
// 运行什么模型,就需要安装什么模型的依赖
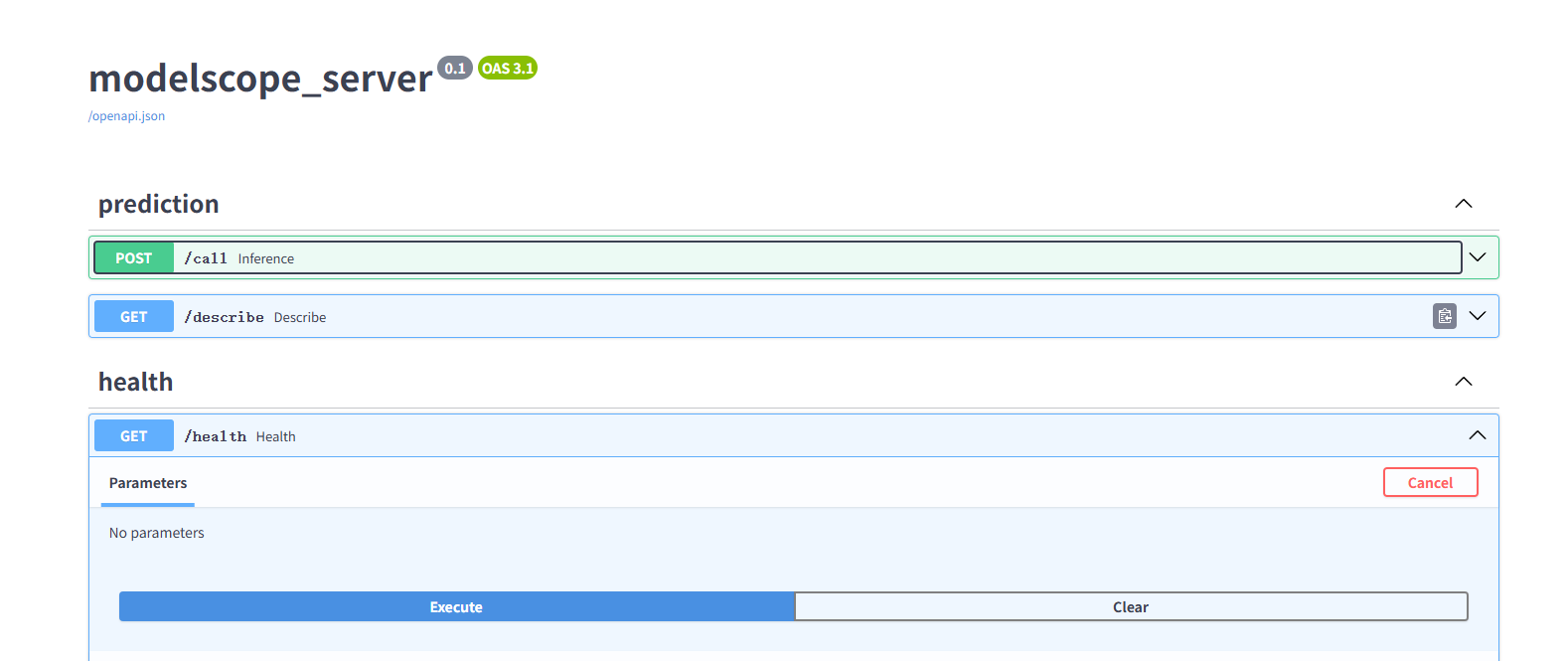
服务默认监听8000端口,您也可以通过--port改变端口,默认服务提供两个接口,接口文档您可以通过 http://ip:port/docs查看 通过describe接口,可以获取服务输入输出信息以及输入sample数据,如下图:
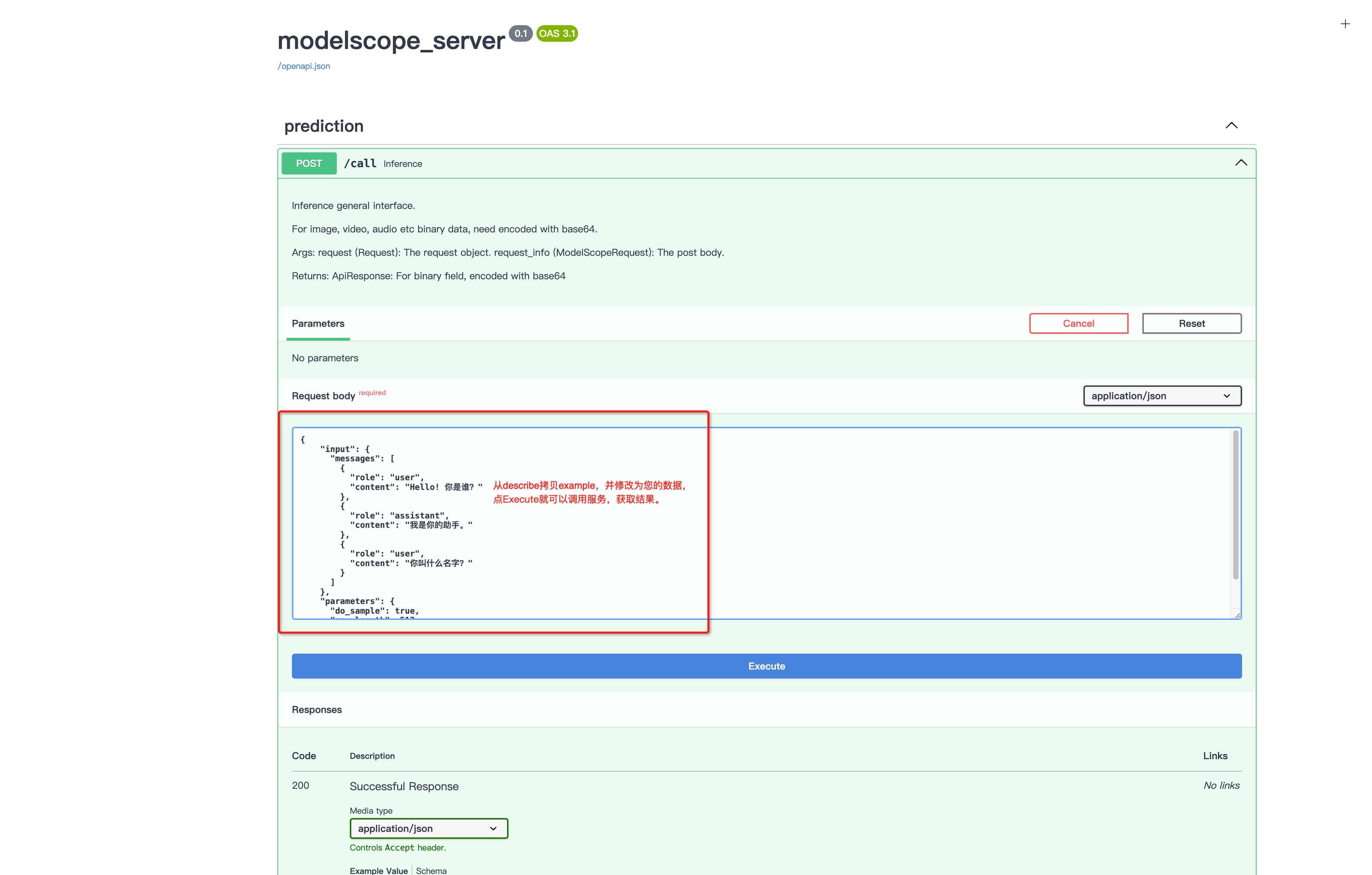
服务调用接口,可以直接拷贝describe接口example示例数据,调用call方法如下图:
# vllm大模型推理
对于LLM我们提供了vllm推理支持,目前只有部分模型支持vllm。
可以通过设置环境变量使得vllm从www.modelscope.cn下载模型。
启动普通server
VLLM_USE_MODELSCOPE=True python -m vllm.entrypoints.api_server --model="Qwen/Qwen-7B-Chat" --revision="v1.1.8" --trust-remote-code
启动openai兼容接口
VLLM_USE_MODELSCOPE=True python -m vllm.entrypoints.openai.api_server --model="Qwen/Qwen-7B-Chat" --revision="v1.1.8" --trust-remote-code
WARNING
vlm不支持linux系统,未进行测试